润乾计算表是一款非常好用的数据计算工具。对于有一些非常难的数据计算你可以使用润乾计算表轻松计算。该程序的自动化程度高于用户经常使用的Excel。它非常适合分层数据计算和复杂的逻辑计算。同时,用户还可以...
基本信息
评分 7
润乾计算表是一款非常好用的数据计算工具。对于有一些非常难的数据计算你可以使用润乾计算表轻松计算。该程序的自动化程度高于用户经常使用的Excel。它非常适合分层数据计算和复杂的逻辑计算。同时,用户还可以在分布式免费计算领域中使用它。与Excel协作可以大大提高用户的工作效率;使用计算表,您可以制作电子表格,并对表中的数据执行分析或结构化计算。计算表中的数据将根据结构进行存储,以便可以分析和计算各种类型的派生数据,例如,同期比较,余额计算和股份分配。各种转换,例如连接;新版本更新后,其工作特性类似于Excel。原始数据和计算表达式都存储在网格中,可以轻松设计和管理表或计算数据;您可以直接导入文本文件或Excel文件,该文件支持在计算表中直接转换数据,需要它的用户可以下载体验。
通过分层设置将行与行相关联,多层结构可以更全面地描述实际业务中的数据
自由便捷的群组操作,性能卓越,易于使用
真正的分组,允许对分组中的数据以及分组后的每个分组进行排序和过滤
以下是某个地方一个月的每月平均温度记录(°F):
按年份分组,并计算每年最高和最低温度的平均值。结果如下:
真实计算表使用实数分组,允许在不限制层数的情况下对多层进行分组。这样,您可以根据需要执行分组,拆卸,重新分组等操作。分组后,您还可以执行各种数据操作,例如对组中的记录进行排序和过滤,或者对每个组进行分组和过滤,这非常方便。
例如,您可以按平均最低温度的降序对每个组中的数据进行排序,并对每年的数据进行排序。为此,选择D3进行降序排序,然后将执行每个组中的记录。结果如下:
同位行和同伦
的具有相同业务状态的数据设置在同一行中
同时处理同伦行中同伦的外观属性
通过在同一位置使用公式迁移,一次完成相同业务逻辑的计算
以下是一些棒球队的投手技术数据。现在,您需要计算每个投手的防御率(平均得分[ERA]):
为了计算ERA,您首先需要计算投球的IP,并每1轮将其小数部分转换为0.3,公式为IP2=int(IP)+(IP-int(IP))/0.3,然后计算ERA,公式为ERA=9*ER/IP2。在计算表中,您只需要在任何奇偶校验行中填写公式。例如,用E3=int(C3)+(C3-int(C3))/0.3填写公式,然后填写F3。公式=9*D3/E3:
即使他们位于不同的组中,也会计算所有玩家的ERP数据,然后将两个网格的显示格式设置为“#。##”,字体将以粗体显示并设置为居中对齐,结果如下面所述:
(2)计算表中位于同一位置的行存储具有相同业务背景的数据。并排的行可以存在于多个组中。如果在同一行的单元格中填写公式或修改显示属性,则将同时处理同一行中同一行中所有相同的单元格。通过设置奇偶校验行,可以批量处理表中数据,大大提高了效率。
公式的智能分析
使用奇偶校验行和级别的设置智能地了解计算的真正目的
自动迁移同位公式,无需复制和粘贴
在这里,我们来了解计算表文件的样式:
在左侧窗口中,右侧区域是网格区域。网格区域是当前打开的计算表文件。左侧区域是分层区域,显示计算表文件的分层结构。在右侧窗口中,上部区域是单位。在单元属性区域中,您可以查看和设置单元的各种属性。选择以下区域时,可以自动对单元格统计区域进行计数,包括总计,平均值,计数,也可以将其添加到所选单元格统计区域中。自定义统计表达式。
在计算表的计算表文件中,数据是根据层次结构而不是简单的二维表按组存储的。
计算表中的每一行在左侧的层次结构区域中都有一个数字,这是该行的延续,而延续数字所在的列就是该行的层次结构。例如,在第三行中,继续编号为1,级别为2;在第二行中,连续数为1,级别也为1。在第一行中,连续数为1,级别为0。关于连续数和层次结构等概念,还有更多内容。esCalc结构的层次结构中的详细说明。
可以注意到,在层次结构区域中的某些连续数字之后有一个减号,表示该行是分组的行,并且其组中的所有行均已展开并显示,例如上方网格中的第二行行。单击已分组的行的继续编号以缩小组中的行。单击第二行的继续编号后的网格如下:
您会看到加利福尼亚州以下的城市已经缩小并且没有显示,并且第2行中的延续线之后的符号已变为加号+。如果再次单击第2行的延续,则可以再次展开组中的行。
多层表可以更直观地表示数据的结构,并且更容易执行各种更复杂的计算,例如与上一期间比较,与同一期间比较等等。
参考现有数据
打开计算表,在菜单栏中单击“文件”>“以其他格式打开文件”,
可以使用Txt文件,Excel文件或CSV文件,您可以选择是否在数据中包含标题行。
例如,以下文本文件states.txt:
在文本文件中,每行用回车符分隔,每列用制表符分隔。如果在打开文件时选择“不带标题的文本”,则生成的计算表如下:
01ABCDEF
1-1
12StateIdName人口人口AbbrAreaCapital
135加利福尼亚州37253956CA163700萨克拉曼多
149佛罗里达州18801310FL65755塔拉哈西
1513Illinois12830632IL54826Springfield
321632纽约19378102NY54556阿尔巴尼
1743得克萨斯州25145561TX268820奥斯丁
因为选择了不带标题的文本,所以生成计算表时,文本文件中的所有行都将用作数据行,并将按顺序导入到网格中。在所有数据行之前,将有一个空白标题行。如果选择打开带标题的文本,则文本文件中的第一行将作为列标题导入,结果如下:
01ABCDEF
1-1StateIdNamePopulationAbbrAreaCapital
125加利福尼亚37253956CA163700萨克拉曼多
139佛里达州18801310FL65755塔拉哈西
1413伊利诺伊州12830632IL54826斯普林菲尔德
321532纽约19378102NY54556阿尔巴尼
1643德克萨斯州25145561TX268820奥斯丁
您也可以复制外部数据并将其粘贴到计算表中。例如,文本文件records.txt中的数据如下:
复制此文本文件中的所有文本,并在计算表中创建一个新的网格文件,如下所示:
01ABCDE
1-1
12
二十三
选择单元格B2,在右键单击菜单中单击“同质单元”粘贴,或同时按Ctrl+Alt+V执行同位体粘贴。
01ABCDE
1-1
12TX休斯顿
13TX达拉斯
14TX埃尔帕索
15TX奥斯丁
16CAS圣地亚
17CAFresno
18卡桑·何塞
19TN孟菲斯
110TNNashville
211
同执行奇偶校验粘贴时,如果网格中的记录行不足以粘贴数据,则行将自动添加到组中。复制外部数据时,还可以使用其他格式的文件或在数据库浏览器中进行复制。
分组和唯一性
统计在统计中,有时必须根据某些规则对数据进行分组,然后为每个组处理数据。在计算表中,可以使用分组操作对行进行分组。
选择TitleS打开GymScores.txt,或直接打开esCalc_abc_1.gex。
01AC
1-1NameEventScore
12GraceMillerVault14.0
13凯拉·罗德里格斯(KaylaRodriguezVault)14.575
Ka14KaylaRodriguez高低杠14.675
Ka15KaylaRodriguez平衡梁13.975
16KaylaRodriguez地板14.4
劳伦17劳伦·戴维斯避难所14.27
18GraceMiller地板13.975
19格蕾丝·米勒不均匀杠12.875
劳伦110劳伦·戴维斯地板13.
111GraceMiller平衡木13.1
Daniel112丹尼尔·史密斯双杠14.375
劳伦113劳伦·戴维斯平衡梁15.225
劳伦114劳伦戴维斯高低杠14.275
这是运动员表现表。在表中,第一行是数据的每一列的标题。从第二行开始,每一行都是运动员某项赛事的表现。这些行类似于数据库表中的记录。
现在,根据播放器的名称将网格中的行分组。为此,请选择单元格A2,然后在右键菜单中单击“操作”>“组”以执行组操作。弹出组操作面板,如下所示:
分组分组时,可以选择是否先排序,然后取消选中“先排序后先排序”。
012ABC
1-1NameEventScore
1-2格雷斯·米勒
13GraceMillerVault14.
1-4凯拉·罗德里格斯(KaylaRodriguez)
Ka15KaylaRodriguezVault14.575
Ka16KaylaRodriguez高低杠14.675
Ka17KaylaRodriguez平衡梁13.975
Ka18KaylaRodriguez地板14.4
1-9劳伦·戴维斯
劳伦110劳伦·戴维斯保险库14.275
1-11格蕾丝·米勒
112格蕾丝·米勒地板13.975
113GraceMiller高低杠12.875
1-1劳伦·戴维斯(LaurenDavis)
115劳伦·戴维斯地板13.0
1-1格蕾丝·米勒
117GraceMiller平衡木13.1
-181-18丹尼尔·史密斯
119丹尼尔·史密斯双杠14.375
1-20劳伦·戴维斯
劳伦121劳伦·戴维斯平衡梁15.225
劳伦122劳伦·戴维斯高低杠14.275
将此网格另存为esCalc_abc_2.gex,以供以后使用。结果,根据运动员的姓名将每行的数据分组,并在每组的顶部添加新行。每个组的名称均已填写。小三角形是主单元格标记,表示在分组的行中,名称所在的单元格是主单元格。在层次结构区域中,您可以看到原始数据行已从第一层更改为第二层,并且已分组的行作为新的层次结构插入到数据行的前面。
可以看出,这次没有对分组前的记录进行排序,只有具有相同名称的相邻行才被分组为同一组。这可能导致重复的分组行。例如,第2、11和16行都是GraceMiller分组。行。
重新打开网格文件esCalc_abc_1.gex,或按Ctrl+z撤消刚刚执行的分组操作。选择A2。在初始计算表中,再次执行分组操作。这次,选择“在排序后在组之前排序”。分组后的计算表如下:
01BC
1-1NameEventScore
1-2丹尼尔·史密斯
丹尼尔13丹尼尔·史密斯双杠14.375
1-4格蕾丝·米勒
15GraceMillerVault14.0
16GceMiller地板13.975
17格蕾丝·米勒不均匀杠12.875
18GraceMiller平衡木13.1
1-9凯拉·罗德里格斯(KaylaRodriguez)
Ka110KaylaRodriguezVault14.575
Ka111KaylaRodriguez高低杠14.675
Ka112KaylaRodriguez平衡木13.975
113KaylaRodriguez地板14.4
1-14伦·戴维斯(LaurenDavis)
劳伦115劳伦·戴维斯保险库14.275
116伦·戴维斯地板13.0
117劳伦·戴维斯平衡梁15.225
劳伦118劳伦·戴维斯不平衡杆14.275
在结果中,在分组之前,每一行均按运动员姓名的升序排列。
如果我们想知道哪些运动员参加了比赛而又不关心他们参加了多少比赛,那么我们可以进行独特的操作。
请重新打开esCalc_abc_1.gex,选择单元格A2,然后单击右键菜单中的“操作”>“区分”以执行唯一操作。执行该操作时,将弹出唯一的操作面板,并选择执行重复的Distinct:
目前未选择仅相邻。执行唯一操作后的结果如下:
01ABC
1-1NameEventScore
12GraceMillerVault14.0
13凯拉·罗德里格斯(KaylaRodriguezVault)14.575
劳伦14劳伦·戴维斯避难所14.275
丹尼尔15丹尼尔史密斯双杠14.375
通过与原始计算表进行比较,我们可以看到,根据名称对重复数据删除进行了独特的操作后,每个运动员仅留下了第一行数据,而其他行被删除了。我们可以清楚地知道总共有4位运动员。
排序和对齐
数据填入网格后,不一定是有序的。为了便于统计,通常有必要在统计之前对数据进行排序。
如何对计算表中的数据进行排序?我们仍然使用上一章中使用的体操成绩表来查找。选择标题文本以打开GymScores.txt,或直接打开计算表esCalc_abc_1.gex,计算表如下:
01ABC
1-1NameEventScore
12GraceMillerVault14.0
13凯拉·罗德里格斯(KaylaRodriguezVault)14.575
Ka14KaylaRodriguez高低杠14.675
Ka15KaylaRodriguez平衡梁13.975
16KaylaRodriguez地板14.4
劳伦17劳伦·戴维斯避难所14.275
18GraceMiller地板13.975
19格蕾丝·米勒不均匀杠12.875
劳伦110劳伦·戴维斯地板13.0
111GraceMiller平衡木13.1
Daniel112丹尼尔·史密斯双杠14.375
劳伦113劳伦·戴维斯平衡梁15.225
劳伦114劳伦戴维斯高低杠14.275
例如,按名称对数据行进行排序。选择单元格A2,然后在右键菜单中单击“操作”>“排序”以执行排序操作。确认排序操作后,如下所示弹出操作面板:
在排序操作面板中,您可以看到选定的排序单元,并设置是否在排序时增加顺序。现在选择Asc。确认操作后,结果如下:
01ABC
1-1NameEventScore
丹尼尔12丹尼尔·史密斯双杠14.375
13GraeMillerVault14.0
G14丝·米勒地板13.975
G15格蕾丝·米勒高低杠12.875
16GraceMiller平衡木13.1
Ka17KaylaRodriguezVault14.575
Ka18KaylaRodriguez高低杠14.675
Ka19KaylaRodriguez平衡木13.975
110KaylaRodriguez地板14.4
劳伦111劳伦戴维斯保险柜14.275
劳伦112劳伦·戴维斯地板13.0
劳伦113劳伦·戴维斯平衡梁15.225
劳伦114劳伦戴维斯高低杠14.275
从结果中可以发现,网格中的行根据名称的字母顺序以升序排序,并且同一运动员的结果保持原始顺序。
然后继续按照得分的降序对计算表中的数据行进行排序。为此,选择C2进行排序操作,将操作面板中的排序单元格设置为C2,删除Asc选项,并在执行后确认结果:
01AC
1-1NameEventScore
劳伦12劳伦·戴维斯平衡梁15.225
Ka13KaylaRodriguez高低杠14.675
Ka14KaylaRodriguezVault14.57
15KaylaRodriguez地板14.4
Daniel16丹尼尔·史密斯双杠14.375
劳伦17劳伦·戴维斯避难所14.275
劳伦18伦·戴维斯不平衡杆14.275
19GraceMillerVault14.0
110格蕾丝·米勒地板13.975
111凯拉·罗德里格斯(KaylaRodriguez)平衡木13.975
112GraceMiller平衡木13.1
113LaurenDavis地板13.0
114格蕾丝·米勒(GraceMiller)不均匀杆12.875
在排序操作中,顺序只能选择升序或降序,这样的排序结果不一定是我们所需要的。例如,我们要按LaurenDavis,GraceMiller,KaylaRodriguez的顺序对运动员的表现进行排序,并删除其他人的表现。此时,可以使用注册操作。在上表中,选择名称所在的单元格。例如,选择A10,然后在右键菜单中单击“操作”>“对齐”以执行对齐操作。在操作面板中设置以下内容:
在对齐顺序中,依次输入所需的运动员名称。排序时,请注意不要勾选“保留所有频段”,否则将删除不按顺序的数据排序后的结果如下:
01ABC
1-1NameEventScore
劳伦12劳伦·戴维斯平衡梁15.225
劳伦13劳伦·戴维斯避难所14.275
劳伦(Lauren)14劳伦·戴维斯(LaurenDavis)
劳伦15劳伦戴维斯地板13.0
16GraceMillerVault14.0
ceMiller地板13.975
18GraceMiller平衡木13.1
19格蕾丝·米勒不均匀杠12.875
Ka110KaylaRodriguez高低杠14.675
111凯拉·罗德里格斯(KaylaRodriguezVault)14.575
112KaylaRodriguez地板14.4
113.凯拉·罗德里格斯(KaylaRodriguez)平衡木13.975
通过比对,根据运动员的姓名对表中的数据进行重新排序,并删除不在比对顺序中的组。
排序操作和对齐操作也可以在分组的行上执行。打开esCalc_q03_2.gex,计算表如下:
012ABC
1-1NameEventScore
1-2格雷斯·米勒
13GraceMillerVault14.0
1-4凯拉·罗德里格斯(KaylaRodriguez)
15凯拉·罗德里格兹(KaylaRodriguezVault)14.575
Ka16KaylaRodriguez高低杠14.675
Ka17KaylaRodriguez平衡梁13.975
Ka18KaylaRodriguez地板14.4
1-9劳伦·戴维斯
劳伦110劳伦·戴维斯保险库14.275
1-11格蕾丝·米勒
112格蕾丝·米勒
113GracMiller高低杠12.875
1-14劳伦·戴维斯(LaurenDavis)
115劳伦·戴维斯地板13.0
1-16格蕾丝·米勒
117GraceMiller平衡木13.1
-181-18丹尼尔·史密斯
119丹尼尔·史密斯双杠14.375
1-20劳伦·戴维斯
劳伦121劳伦·戴维斯平衡梁15.225
劳伦122劳伦·戴维斯高低杠14.275
该计算表在分组之前不会对记录进行排序。此时,如果您在分组行中选择主单元格(例如A4),请执行排序操作。排序时,删除Asc选项:
结果如下:
012ABC
1-1NameEventScore
劳伦·戴维斯(LaurenDavis)
劳伦13劳伦·戴维斯避难所14.275
1-4劳伦·戴维斯
劳伦15劳伦戴维斯地板13.0
劳伦·戴维斯(LaurenDavis)
劳伦17劳伦戴维斯平衡梁15.225
劳伦18劳伦·戴维斯不平衡杆14.275
1-9凯拉·罗德里格斯(KaylaRodriguez)
Ka10KaylaRodriguezVault14.575
Ka111KaylaRodriguez高低杠14.675
Ka112KaylaRodriguez平衡木13.975
113KaylaRodriguez地板14.4
1-14格蕾丝·米勒
115GraceMillerVault14.0
1-16格蕾丝·米勒
117格蕾丝·米勒地板13.975
118格蕾丝·米勒不均匀杠12.875
-191-19格雷斯·米勒
120raceMiller平衡木13.1
1-21丹尼尔·史密斯
Daniel122丹尼尔·史密斯双杠14.375
您可以看到,按降序对分组的行进行排序时,该组中该组中记录行的顺序没有变化,但是会随其分组的行一起移动。
然后在分组行中,选择名称所在的主题,例如A21,并执行对齐操作。在弹出的操作面板中,按照LaurenDavis,GraceMiller,KaylaRodriguez的顺序进行先前的选择,并且不要选择Retainallband。执行后的结果如下:
012ABC
1-NameEventScore
劳伦·戴维斯(LaurenDavis)
劳伦13劳伦·戴维斯避难所14.275
1-4劳伦·戴维斯
劳伦15劳伦戴维斯地板13.0
劳伦·戴维斯(LaurenDavis)
劳伦17劳伦戴维斯平衡梁15.225
劳伦18劳伦·戴维斯不平衡杆14.275
1-格蕾丝·米勒
110GraceMillerVault14.0
1-11格蕾丝·米勒
112格蕾丝·米勒地板13.975
113GraceMiller高低杠12.875
1-14格蕾丝·米勒
115GraceMiller平衡木13.1
1-16凯拉·罗德里格斯(KaylaRodriguez)
117·凯拉·罗德里格斯(KaylaRodriguezVault)14.57
118·凯拉·罗德里格斯(KaylaRodriguez)不均匀酒吧14.675
119.凯拉·罗德里格斯(KaylaRodriguez)平衡木13.975
120·凯拉·罗德里格斯(地板)14.
对使用对齐操作调整分组行的顺序时,组中的数据行将与整个组一起移动,并且组中的顺序将不受影响。
在计算表中使用表达式
数据在数据分析中,通常需要使用原始数据来计算所需的结果。
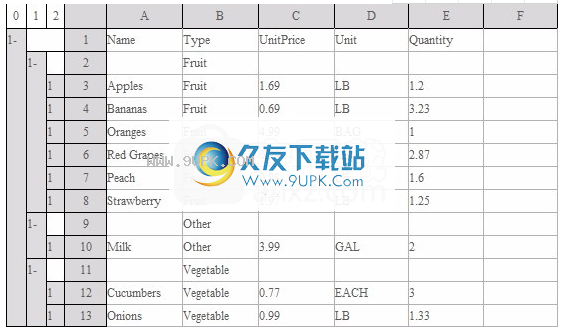
打开esCalc_abc_3.gex,我们看下面的计算表:
012ABCDEF
1-1NameTypeUnitPriceUnitQuantity
1-2水果
苹果13ApplesFruit1.69LB1.2
14香蕉水果0.69LB3.23
15橘子水果4.99BAG1
16红葡萄水果0.99LB2.87
17桃果0.88LB1.6
Stra18草莓水果1.97LB1.25
1-其他
110牛奶其他3.99GAL2
1-11蔬菜
112黄瓜蔬菜0.77EACH3
113洋葱蔬菜0.99LB1.33
在该网格中,食物超市的购物清单信息被记录并按食物类型分组。您也可以选择打开带有标题文本的reciept.txt,然后尝试使用分组操作来生成此计算表。
在第一章中,我谈到了延续性和层次。计算表中的每一行在左侧的分层区域中都有一个数字。这是此行的继续。在上面的计算表中,每行的继续数为1。继续数所在的层次结构列的列。数字是该行的级别,例如第三行,级别为2;例如第二行,级别为1;第一行的级别为0。在此简单的结构化计算表中,相似的数据存储在同一级别的行中。如第2,9,11行,它们都是商品类型的分组行,级别均为1;第3、4、5、6、7、8、10、12、13行,它们都记录了一定的食品购买信息,级别均为2。
中,如果单元格中的单元格字符串以“=”开头,则等号后的字符串将被解析为表达式,并且该单元格的单元格值就是该表达式的计算结果。与Excel相似,在计算表中,如果单元格具有值,则在表达式中,您可以直接将单元格名称称为变量名称。计算表中还有一个以两个e开头的表达式
品质符号“==”。
在购物清单信息网格中,记录了每种食物的单价和购买数量,并且可以基于这些计算出每种食物的价格。计算时,请使用单价*数量并保留两位小数。首先使用以两个等号开头的表达式。在F3中写表达式==round(C3*E3,2)。结果如下:
012ABCDEF
1-1NameTypeUnitPriceUnitQuantity
1-2水果
13ApplesFruit1.69LB1.22.03
14香蕉水果0.69LB3.232.23
15橘子水果4.99BAG14.99
16红葡萄水果0.99LB2.872.8
17桃果0.88LB1.61.41
Stra18草莓水果1.97LB1.252.46
1-9其他
110牛奶其他3.99GAL27.98
1-11蔬菜
112黄瓜蔬菜0.77EACH32.31
113洋葱蔬菜0.99LB1.331.32
我可以看到,在F3的结果中,计算出了苹果的价格。应该注意的是,在与第三行相同的行中,有计算结果。在F列中选择这些单元格以查看其表达式。您可以看到F7中的表达式为==圆(C7*E7,2),而F10中的表达式为==圆(C10*E10,2),...在相同的简单结构计算表中在同一行中,将自动设置并自动更改同一列中单元格的表达式。在F7和F10中计算各行中货物的总价。
当在一个单元格中使用两个以等号开头的表达式时,它称为链接计算单元格,并且在右下角将生成一个蓝色三角形链接计算单元格标记。在计算表中的简单结构的计算表中,同一行和同一列中的单元格称为同位元,同位元中的表达式根据含义自动更改,而无需手动调整。关于奇偶关系和同构性,在esCalc结构的奇偶关系中有更详细的描述。
我们已经计算了网格中每种商品的价格,那么如何计算每种商品的总价格呢?这次使用等号的表达式。为此,在F1和F2中,编写相同的表达式={F3}.sum(),结果如下:
012ABCDEF
1-1NameTypeUnitPriceUnitQuantity27.57
1-2水果15.96
苹果13ApplesFruit1.69LB1.22.03
14香蕉水果0.69LB3.232.23
15橘子水果4.99BAG14.99
红色16红葡萄水果0.99LB2.872.84
17桃果0.88LB1.61.41
Stra18草莓水果1.97LB1.252.46
1-9其他7.98
110牛奶其他3.99GAL27.98
1-11蔬菜3.63
112黄瓜蔬菜0.77EACH32.31
113洋葱蔬菜0.99LB1.331.32
F2计算水果的总价,其同位体F9和F11也自动设置表达式以计算其他食品和蔬菜的总价。在F1中,计算所有食物的总价。在表达式中,{F3}代表该组中F3的所有同位体,并且可以对结果集中的集合执行各种聚合操作,例如{F3}.sum(),{F3}.count(),{F3}.avg(),{F3}.max()等。表达式写在不同的分组行中,并且可以计算每个分组的总数;写在第1行的第0层行中,可以计算出所有食品的总价。在esCalc结构的相关功能中,引入了更多与层次结构相关的功能。
可以注意到,由于在F1和F2中使用了以等号开头的表达式,因此在F1,F2,F9和F10的右下角没有三角形标记。这样的单元称为计算单元。
在下方,苹果暂时打折了价格。将单价从1.69元调整为1元,并将单元格C3中的值更改为1。结果如下:
012ABCDEF
1-1NameTypeUnitPriceUnitQuantity27.57
1-2水果15.96
Apple13ApplesFruit1LB1.21.2
14香蕉水果0.69LB3.232.23
15橘子水果4.99BAG14.99
红色16红葡萄水果0.99LB2.872.84
17桃果0.88LB1.61.41
Stra18StrawberryFruit1。
97LB1.252.46
1-9其他7.98
110牛奶其他3.99GAL27.98
1-11蔬菜3.63
112黄瓜蔬菜0.77EACH32.31
113洋葱蔬菜0.99LB1.331.32
您可以看到,在修改单元格C3之后,在F3中计算的苹果总价格也发生了变化,但是在F2中计算的水果总价格和在F1中计算的食品总价格并未更新。链接的计算单元格类似于Excel中的计算单元格,并且在修改被调用单元格的值时将对其进行处理和重新计算。输入表达式后,普通计算单元将只计算一次。
在计算表中,由于需要更多资源,因此更常用计算网格。如果网格中用于计算的数据可能会更改,则需要使用链接的计算网格以避免计算错误。
打开esCalc_abc_4.gex,网格如下:
012ABCD
1-1州年人口
1-2加州
13加利福尼亚州199029760021
14加利福尼亚200033871648
15加利福尼亚201037253956
1-6纽约
17纽约199017990455
18纽约200018976457
19纽约201019378102
1-10德州
111德克萨斯州199016986510
112德克萨斯州200020851820
113德克萨斯州201025145561
计算表中的信息是某些州以前的人口普查的统计数据。您也可以选择打开带有标题文本的人口.txt,尝试通过分组来生成计算表,并在表的右侧添加一列。为此,您可以选择第三列中的任何单元格,例如,选择单元格C1并同时按Alt+Shift+插入。
在D13网格中,设置表达式=C13-C12,计算总体增量,结果如下:
012ABCD
1-1州年人口
1-2加州
13加利福尼亚州19902976002129760021
14加利福尼亚2000338716484111627
15加利福尼亚2010372539563382308
1-6纽约
17纽约199017990455-19263501
18纽约200018976457986002
19纽约201019378102401645
1-10德州
111德克萨斯州199016986510-2391592
112德克萨斯州2000208518203865310
113德克萨斯州2010251455614293741
您可以看到,D12的同型性也可以通过表达式进行迁移,以计算总体增加。迁移表达式时,将种群增量视为当前种群减去当前种群的先前同态。
仔细观察可以发现在D7和D11中发生了问题,因为最后的同态性不在同一组中。此时,可以通过限制同构性来避免错误。为此,将D13中的表达式修改为=C13-C12[A10],并且上轮廓数据C12限于当前分组层A10。修改后,计算结果如下:
012ABCD
1-1州年人口
1-2加州
13加利福尼亚州19902976002129760021
14加利福尼亚2000338716484111627
15加利福尼亚2010372539563382308
1-6纽约
17纽约19901799045517990455
18纽约200018976457986002
19纽约201019378102401645
1-10德州
111德克萨斯州19901698651016986510
112德克萨斯州2000208518203865310
113德克萨斯州2010251455614293741
通过用级别限制同伦,它避免了表达式自动更改时可能发生的错误,并可用于正确处理诸如上一个期间之类的计算。在简单计算表中,行之间的关系相对简单,同伦的判断也相对简单。如果您想了解更复杂的功能的使用,请参考esCalc结构的相关功能。
1.用户可以单击本网站提供的下载路径下载相应的程序安装包
2,只需使用解压功能打开压缩包,双击主程序进行安装,并弹出程序安装界面
3.同意协议条款,然后继续安装应用程序,单击同意按钮
4.您可以单击浏览按钮,根据需要更改应用程序的安装路径。
5.弹出应用程序安装进度栏加载界面,等待加载完成
6.根据提示单击“安装”,弹出程序安装完成界面,单击“完成”按钮。









![钢管码单计算表 免安装[钢管码单计算器]](http://img.gz85.com/20210302/20210302150722594.gif)