FreeOCR是一款能够轻松进行ocr文字识别的软件。一款专业的ocr文字识别工具FreeOCR。该软件可以帮助用户快速从图片/PDF文件中识别文本内容。您也可以直接通过扫描功能直接连接扫描仪以进行扫...
基本信息
评分 8
FreeOCR是一款能够轻松进行ocr文字识别的软件。一款专业的ocr文字识别工具FreeOCR。该软件可以帮助用户快速从图片/PDF文件中识别文本内容。您也可以直接通过扫描功能直接连接扫描仪以进行扫描和识别。它具有简单直观的操作界面。打开要扫描的文件,然后选择OCR引擎以开始识别。可以将标识的内容设置为字体,编辑并保存到剪贴板,以进行基本编辑。值得一提的是,该程序支持多种扫描引擎,例如英语,丹麦语,德语,芬兰语,法语,意大利语等,以满足各种语言的识别需求,有学习经验的朋友需要快速下载!
OCFreeOCR支持从大多数Twain扫描仪进行扫描,还可以打开大多数扫描的PDF和多页Tiff图像以及流行的图像文件格式。FreeOCR输出纯文本,可以直接导出为MicrosoftWord格式。
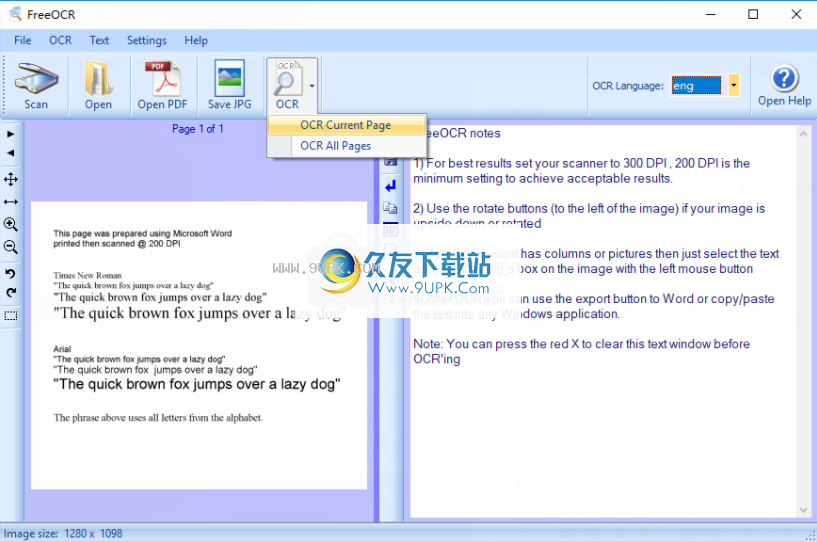
OCFreeOCR非常易于使用。如果将鼠标悬停在它们上方,将说明所有按钮。
首先打开一个文件

扫描-用于扫描纸张图像,这需要Twain兼容的扫描仪。
开放式负载
ng图像,例如Tiff,Jpeg,Bmp。FreeOCR支持多页的Tiff文档。
打开PDF-用于导入扫描的PDF文档。
光学字符识别
选择您要使用的OCR语言

安装的语言包括:
英语
丹麦文
德国
芬兰
法文
义大利文
荷兰人
挪威
抛光
西班牙文
瑞典
按OCR按钮,然后选择要处理当前页面还是整个文档。
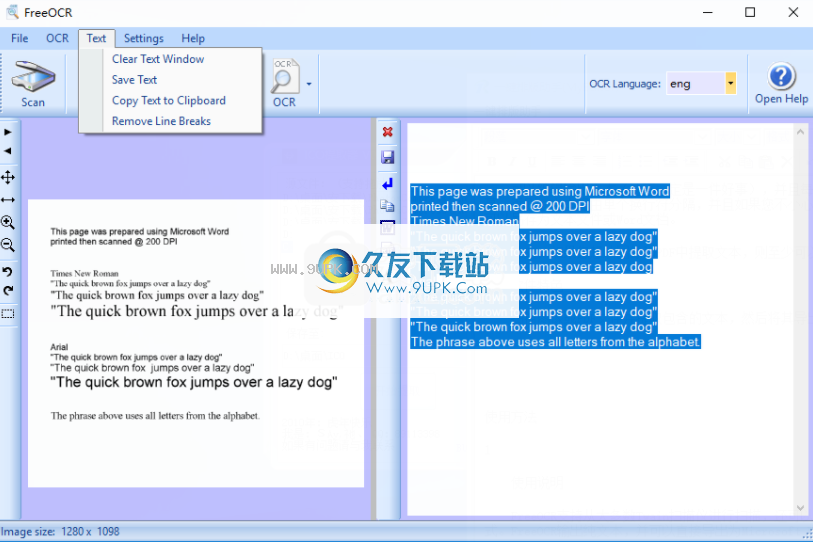
图像显示在左侧,OCR文本显示在右侧
您可以将文本复制并粘贴到任何其他Windows应用程序中,或按文本工具栏上的导出按钮之一。
OCR识别包含图像和列的文档
这是带有虚假UFO报告的PDF,如果您想尝试,可以在此处下载文件(您可能需要右键单击并选择“另存链接为”或“将目标另存为”

我将使用MSWord重新创建文档,但是您可以使用OpenOffice或Publisher,这实际上是支持列和照片的任何程序。
1)现在,我只想转到OCR页面标题

2)然后按“导出到Word”按钮,这将打开一个带有标题的新文档,如果您不使用Word,则只需要打开一个新文档并复制并粘贴文本即可。
3)接下来,我选择OCR并按下“删除换行按钮”,然后在Word中创建一个新的文本框(在Word中为“插入”菜单),然后将文本复制并粘贴到其中,如下所示。

4)现在清除文本窗口,对第二列执行相同的操作

5)现在在照片周围画一个方框以选择图像,然后按选择按钮,然后选择
“将所选内容复制到剪贴板”,这会将所选图像放置在Windows剪贴板上,因此我们现在可以将图像粘贴到Word中(提示:将图片粘贴到文本框中,然后可以轻松地放置它)
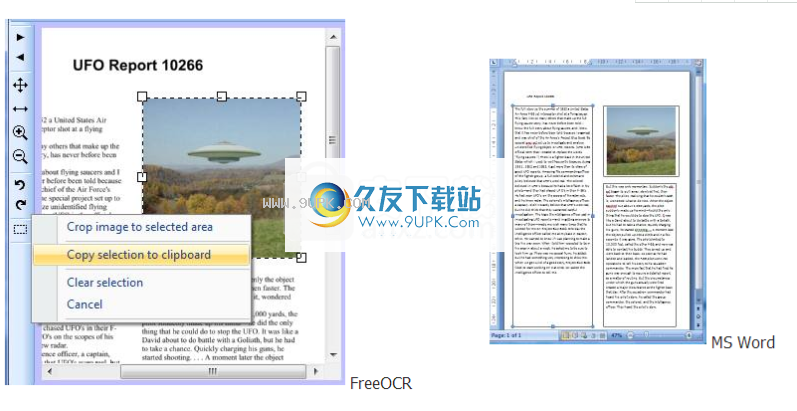
现在,我们已经在Word中拥有了所有的文本和图像,您可以放置文本框并调整字体大小以适合自己的需求,并且别忘了进行最后的校对和拼写检查。
如您所见,要充分利用FreeOCR,需要进行一些手动工作,但我相信您会发现,这比从头开始创建文档要容易得多。
扫描图像或PDF文件并提取包含的文本,然后将其导出为可编辑的形式。
支持多种OCR识别引擎,例如英语,丹麦语,德语,芬兰语,法语,意大利语等。
提供对扫描仪的支持,您可以直接通过扫描仪进行识别扫描。
提供简单直观的用户界面,可以轻松完成扫描识别操作。
支持扫描图像文件和PDF文档,并支持两种扫描方法:扫描当前页面和扫描所有页面。
扫描的文本内容可以快速复制或操作。
1.下载并解压缩该软件,双击安装程序以进入FreeOCR向导界面,然后单击[下一步]。
2,然后进入以下许可协议界面,选中[我接受...]选项,然后继续进行下一个安装。
3.选择其他任务,然后选中“创建桌面”图标选项,以方便启动。
4.准备安装,单击[安装]按钮开始安装。
5.弹出以下FreeOCR安装成功消息,单击[完成]以结束安装。
免费在FreeOCR的帮助下,您可以从图像文件和PDF项目中识别和提取文本。
平稳的安装过程和简单的外观
该应用程序易于安装,更重要的是可以免费使用。用户界面是标准的,此处没有特殊功能。大部分空间是页面和内容的预览区域,而常规功能可从上部工具栏轻松访问。只要确保.NETFramework在您的PC上即可,这是确保功能所必需的。
导入选项
您可以使用扫描仪或在计算机中查找图像或PDF文件。源文件的内容将显示在第一个窗口中,一旦单击“OCR”按钮,您将立即在第二个窗口中看到结果。
编辑和导出功能
输出您可以编辑输出文本(这不一定是一件好事),并且每次插入新信息时,都必须按下红色的小“x”按钮以清除屏幕。否则,文本将由一个换行符分隔,并且如果您不小心单击了“删除换行符”,则将无法使用“撤消”按钮。可以将输出文本另存为文本文件或Word文档。
简而言之,如果要从图像和PDF中提取文本,则至少可以尝试FreeOCR。
1.运行FreeOCR进入软件主界面,如下所示。

2.如果您需要从扫描仪中扫描内容,则可以单击[扫描]按钮进行扫描。
3.单击[打开]按钮以打开要扫描的图像或PDF文件。

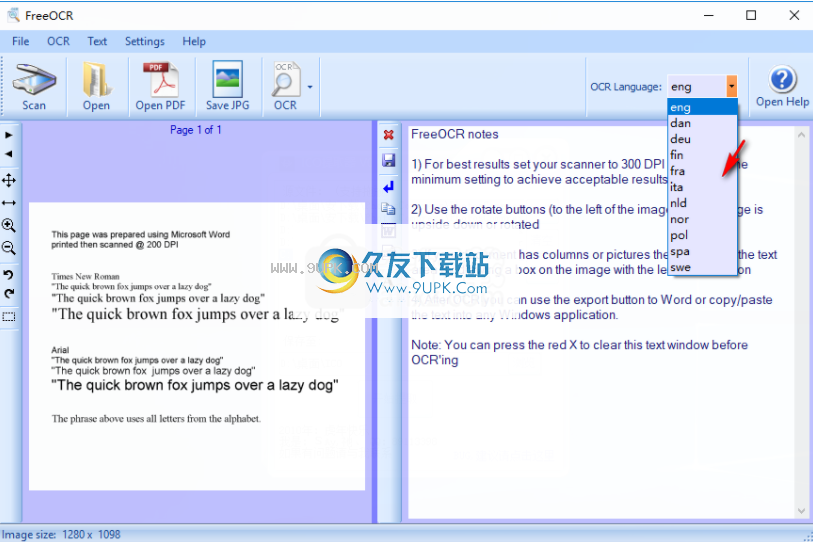
4.选择扫描引擎,提供多种语言,例如英语,您可以根据需要选择。
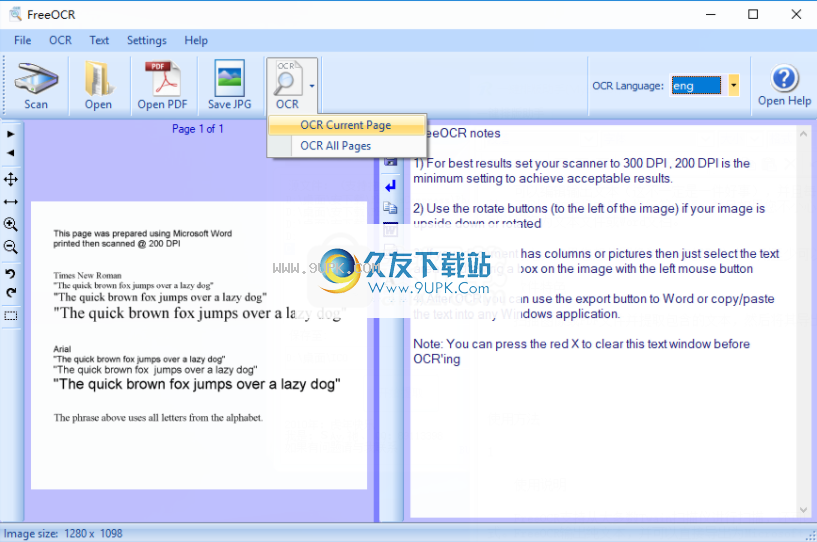
5.在OCR列中,您可以选择扫描当前页面并扫描所有页面。
6.您可以立即扫描并获取扫描结果。

7.用户可以执行诸如保存文本并将文本复制到文本菜单栏下的剪贴板之类的操作。
8.设置,支持更改字体,将字体重置为默认值,打开语言文件夹,文本后处理。